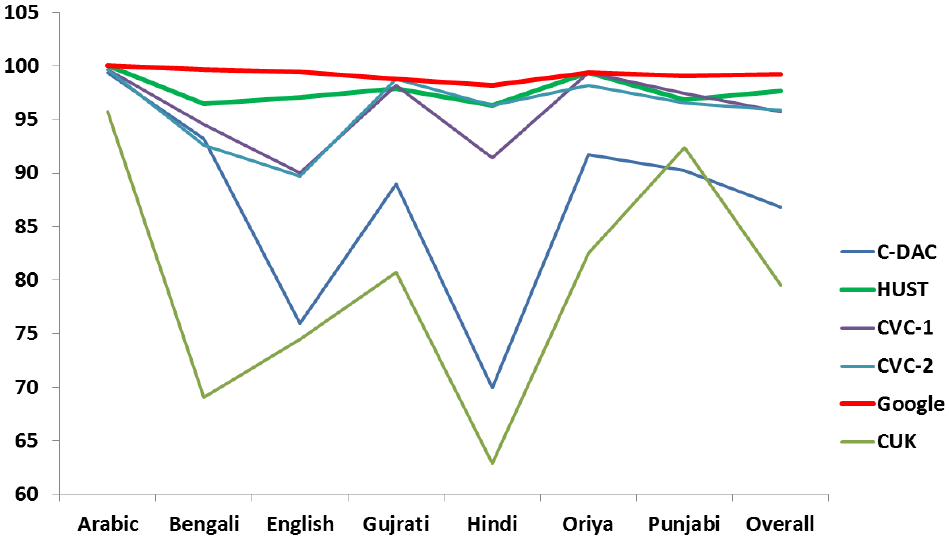
TASK-2 Results
Description: Identifying the combination of scripts used in north India. This task involes identification of seven scripts, namely, English, Hindi, Bengali, Oriya, Gujrathi, Punjabi and Arabic.
Participation Systems
- C-DAC, India: Swapnil Belhe from Centre for Development of Advanced Computing (C-DAC), has participated in all of the four competition tasks.
- HUST, China Baoguang Shi, and his team members Cong Yao, Chengquan Zhang, Wei Shen, Zheng Zhang, and Xiang Bai from Huazhong University of Science and Technology (HUST) have submitted systems by participating in all of the four competition tasks.
- CVC-1 and CVC-2, Spain: Lluis Gomez from the Computer Vision Center at UAB have participated in all of the four competition tasks and submitted two sets of systems for video script identification.
- Google, Inc.: Yuanpeng Li from Google has participated in all four of the competition tasks.
- CUK, India: Manjunath Shantharamu from Central University of Kerala (CUK) has participated in three tasks namely Task-2, Task-3 and Task-4.
| Accuracy (%) |
||||||
|---|---|---|---|---|---|---|
| Scripts | C-DAC | HUST | CVC-1 | CVC-2 | CUK | |
| Arabic | 99.34 | 100.00 | 99.67 | 99.67 | 100.00 | 95.71 |
| Bengali | 93.23 | 96.45 | 94.52 | 92.58 | 99.68 | 69.03 |
| English | 75.95 | 97.07 | 90.03 | 89.74 | 99.41 | 74.49 |
| Gujrathi | 88.99 | 97.86 | 98.17 | 98.78 | 98.78 | 80.73 |
| Hindi | 69.93 | 96.32 | 91.41 | 96.32 | 98.16 | 62.88 |
| Oriya | 91.72 | 99.39 | 99.39 | 98.16 | 99.39 | 82.52 |
| Punjabi | 90.19 | 96.84 | 97.47 | 96.52 | 99.05 | 92.41 |
| Overall | 86.79 | 97.69 | 95.73 | 95.91 | 99.19 | 79.50 |