Important dates:
- Feb 1, 2017 : Website online
- Feb 1, 2017 : Registration Open
- Feb 20, 2017: Sample dataset available
March 15, March 24, April 14
April 21, 2017: Training dataset availableMarch 25, April 3, April 21
April 28 2017: Validation dataset availableMarch 31, April 15, May 1
June 30, 2017: Registration closesApril 5, April 18, May 5,
June 30, 2017: Submission of systemsApril 7, April 20, May 10,
May 20, 2017: Test dataset availableApril 10, April 24, May 17,
June 30, 2017: Submission of results
Latest News
- Feb 1, 2017 : Website online, registration open
- Feb 20, 2017 : Sample Dataset available
- March 15, 2017 : Deadline extension
- March 31, 2017 : Following the extension of the ICDAR2017 full paper submission deadline, the training dataset will now be available on 14th April 2017 to the registered participants
- April 21, 2017 : The training dataset is now available to the registered participants
- April 30, 2017 : The validation dataset is now available to the registered participants
- May 29, 2017 : The test dataset is available after system submission
- May 29, 2017 : Competition deadline extend
Dataset
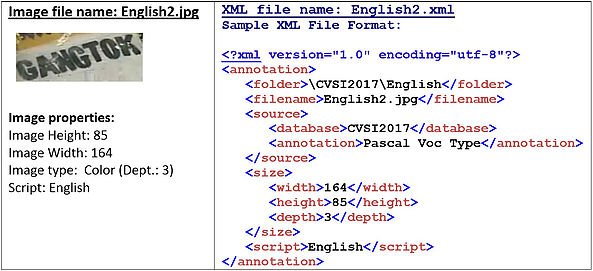
A dataset comprising video words for each of the fifteen scripts will be provided. The dataset contains at least 2000 words (Colour) for each script extracted from various sources (news video, sports video, etc.). The word images will be in JPG format and the corresponding ground truth information will be in XML file. There will be an XML file corresponding to a word image file having the same file name. XML files will contain the script information and image properties. Sample word images for each of the fifteen scripts are shown in the figure below.

Figure: Samples of video word images. 1st row: Arabic, Bengali, English, Gujarati, Hindi; 2nd row: Kannada, Oriya, Punjabi, Tamil; 3rd Row: Telugu, Malayalam, Chinese, Thai; 4th row: Japanese and Korean.
The dataset is divided into three parts namely, Training set (60%), Validation set (10%) and Test Set (30%). The dataset will be made publicly available after the competition for research purpose via the competition website, CVC dataset site and IAPR TC-11.
Dataset Usage:
The CVSI 2017 dataset contains video words of 15 different scripts/languages, namely, English, Hindi(Devnagari), Bengali(Bangla), Oriya, Gujrathi, Punjabi, Kannada, Tamil, Telegu, and Arabic.
The dataset is made publicly available ONLY for RESEACH PURPOSES. Use of dataset for commercial purposes/applications is not allowed.
Reference:
[1] Nabin Sharma, Ranju Mandal, Rabi Sharma, Umapada Pal, and Michael Blumenstein, "ICDAR2015 Competition on Video Script Identification (CVSI 2015)", In Proc. 13th International Conference of Document Analysis and Recognition (ICDAR 2015), pp. 1196-1200, 2015, [pdf].